Inspiration
Ever since ChatGPT exploded onto the AI researching scene and later into the mainstream, I’ve wanted to build a very small subset of something like that.
I lack the amount of compute needed to run something even remotely similar to CHATGPT, so i figured doing something on this scale should be fine.
I was watching the following YouTube Video which was a fascinating and excellent breakdown on how the most basic language models actually function, from tokenisation, to how the statistics of the thing work, how the data is read and arranged, everything is properly broken down in this 2 hour video on the subject.
Now being that I’m not a great python programmer neither do i have the mental capacity to sit through the entire video i decided to do the sensible thing and just clone the repo and have at it. And since most of my creations are anime themed in some way i decided this should be no different.
Technical stuff starts here
I first cloned the repo from GitHub and began taking a look at how it works, studying commands necessary to begin the training of the model and the dataset layout itself.
I then proceeded to download a CSV file dataset of about 72,000 anime character names which is, I’m pretty sure, every single name of every single anime character on MyAnimeList, or something like that.
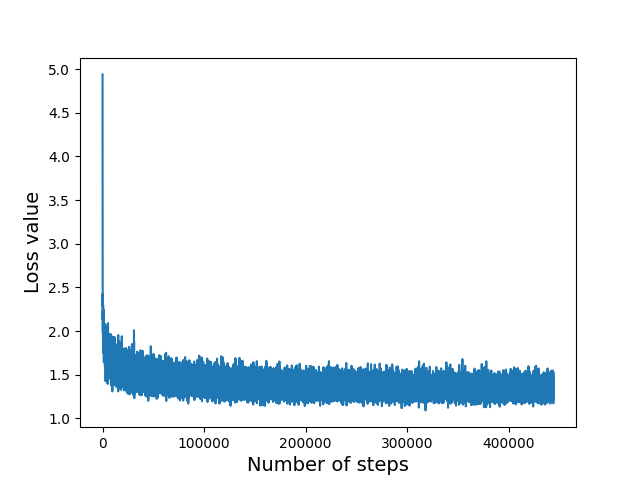
I then started restructuring the Repo to make it a bit more clean, adding a data folder for logging the step/loss of training process so i could later use MatPlot to graph it.
Then i felt it was necessary to have a model folder, in which the new model “Anime” alongside the old model which was provided with the repo “Names” would be stored.
Then i created a few bash scripts, to make running the commands necessary for training the model that much easier.
Then, i decided it would be nice if i could graph the loss function of this training process. That process was made simple thanks to MatPlot. Here’s a link to the Git Repo Link